Memory-efficient computing using pytorch, cuda, and jupyter notebooks
- Neerja Aggarwal
- Jun 16, 2022
- 2 min read

Updated: Oct 17, 2024
The code and algorithms in our Computational Imaging Lab are often written in Python using a framework called Jupyter Notebook. To accelerate the computation, we use the Pytorch library which moves the computation from the CPU to the Nvidia GPUs installed on our lab computers.
Often when we're computing in Pytorch we get this infamous memory error:
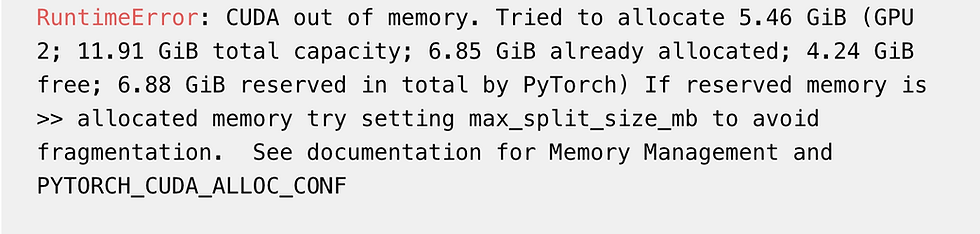
This is especially common if you are writing your own iterative solvers, like we often do in computational imaging research. Creation of new variables inside a for-loop can compound with each iteration and overtake your gpu's memory :*(
And so, today I’m trying to make my code more memory efficient. I ran into several memory issues and didn’t necessarily find everything I was looking for on the internet in one place (stackoverflow, pytorch documentation). And so, I'm writing this short post in case it helps someone else deal with the same issues.
Here are some suggested steps for any code inside a loop:
1. Don’t create new temporary variables on gpu unless necessary. Instead reassign new computed values to update old variables.
Instead of this:
c = a + b # creates a new variableDo this:
a = a + b # updates value of a2. When you do need to create copies of variables (ex: for checkpointing) make sure to get rid of the gradient-graph and store them on cpu.
Instead of this:
xcopy = xDo this:
xcopy = x.detach().cpu()Or:
xcopy = torch.zeros_like(x).to(‘cpu’)3. Use “del [Tensor name]” to delete any variables you don’t need to keep anymore. Use “torch.cuda.empty_cache()” to get rid of cached memory to actually free up the space after deleting.
del x
torch.cuda.empty_cache()4. For imported functions from packages you write: use try/except statements inside functions to help Jupyter delete local variables in case of a Keyboard Interrupt. If you don’t do this, I noticed that calling “torch.cuda.empty_cache()” in the main script won’t necessarily bring memory usage back down to levels before running pkg.functionname. You don’t have to do this for every function, but I recommend it for your main optimization loop or any other long function that is likely to get interrupted.
Inside pkg.py instead of:
def functionname(arguments):
~your code here~
returnDo this:
def functionname(arguments):
try:
~your code here~
return
except KeyboardInterrupt:
torch.cuda.empty_cache()
returnHow to check memory usage:
torch.cuda.empty_cache()
t = torch.cuda.get_device_properties(gpu).total_memory
r = torch.cuda.memory_reserved(gpu)
a = torch.cuda.memory_allocated(gpu)
#print total available memory and used memory (in bytes)
print(t)
print(r)
print(a)Total memory - this is the total memory available
Reserved memory - this is the allocated memory + cache memory
Allocated memory - memory taken up by variables in the environment
Running “torch.cuda.empty_cache()” helps clear the cache and bring reserved and allocated memory to similar levels.
More references:

Comments